
NVIDIA在GTC 2017上发布了基于Volta架构的旗舰计算卡Tesla V100,这可是NVIDIA制造出有史以来最多晶体管的GPU,足足有5120个CUDA单元,比上一代增长了42%,尽管使用了台积电最先进的12nm FFN工艺,但是GPU核心面积已经暴涨至815mm2水平。尽管Tesla V100性能足够强大,不过NVIDIA似乎仍不满足,在一篇研究论文中透露,NVIDIA正在积极探索MCM-GPU的东西,说白了其实就是如何最优化整合多个GPU模块在一起,每个GPU都发挥出百分百的实力。

在GTC 2017上NVIDIA CEO黄仁勋曾说过“目前制造高性能GPU有一个很严重的限制——芯片尺寸的限制,因为目前现有技术的光刻机受限于光刻模板、光刻光源,几乎不可能制造出更大的GPU核心”。单GPU核心价值几乎被榨干殆尽,堆流处理器提升性能即将进入历史的坟墓,因此核心尺寸不能无止境变大已经成为NVIDIA继续提升GPU性能的瓶颈。
因此NVIDIA想到了“胶水**”,就是讲多个GPU核心通过某种方式连接起来,组成一个GPU整体实行运算。这个方法可能就像是之前的GTX 590,两个Fermi架构的GF110-351核心整合到同一块PCB上,不过这样的坏处显而易见,类似于SLI、CF一样,由于两个核心之间连接的数据链路带宽、速度、任务调度存在大量问题,没有产生1 1=2的实际效果,双芯卡的命运也就渐渐没落了。
NVIDIA现在要做的就是探索出一种高效连接多个GPU的方案,MCM-GPU就是这样一个具有前瞻性的实验项目。Multi-Chip-Module Package这种形式的封装其实有点类似于闪存的做法,16层容量不够,那就堆高,堆到64层。这样的好处不仅是制造方式简单,成本有优势,还可以成倍地提高性能。目前,NVIDIA内部的模拟测试中,研究团队已经在研究“堆砌”SMs单元,目前进度已经研发至256组SMs单元(大家算一算有多少个CUDA单元),而Pascal最强的Tesla P100只有56组,Volta最强的Tesla V100也仅仅为80组。说的白了,其实就像我们的高楼大厦,土地面积不够,我们就往高处建,MCM-GPU同样也是叠高,节省核心面积。如果研发过程顺利,以后GPU显卡性能暴增不是梦!
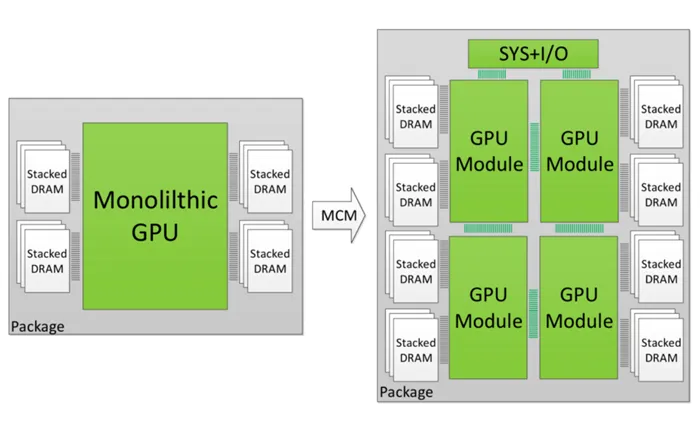
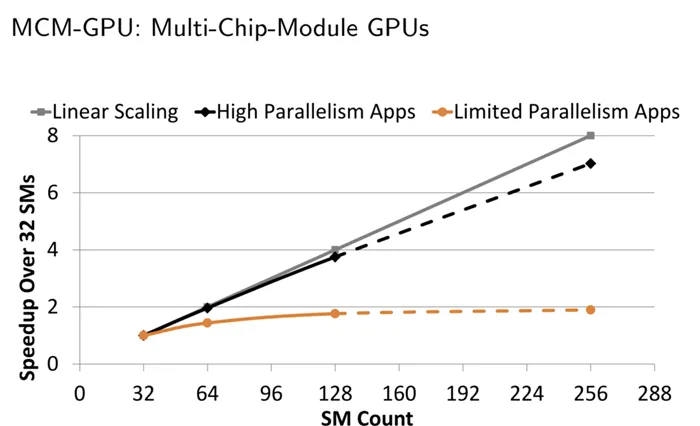
NVIDIA表示MCM-GPU与今天的最大GPU核心相比,可以缩小40-60%的核心面积,将来还可能会用上10nm或者转折性的7nm工艺制造。
此外还有一个很严峻的问题,不同层之间的SM单元到底如何连接,如何使用显存依然是个头疼的问题。因此NVIDIA在将来还有很长的路要走,但是这个MCM-GPU设计有望在明年的CTG大会上与我们见面,适用于下一代显卡架构上。
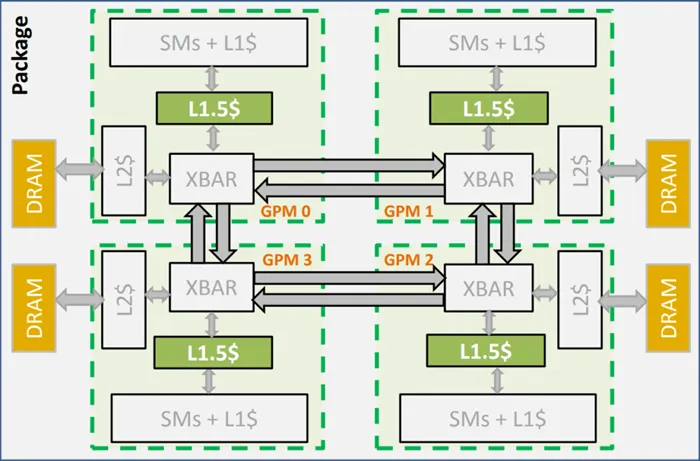
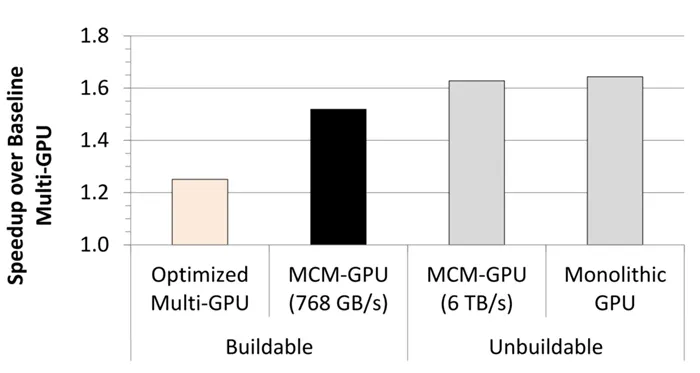
MCM-GPU性能要比普通的多核心GPU性能更好